· Webentwicklung · 7 minuten Lesezeit
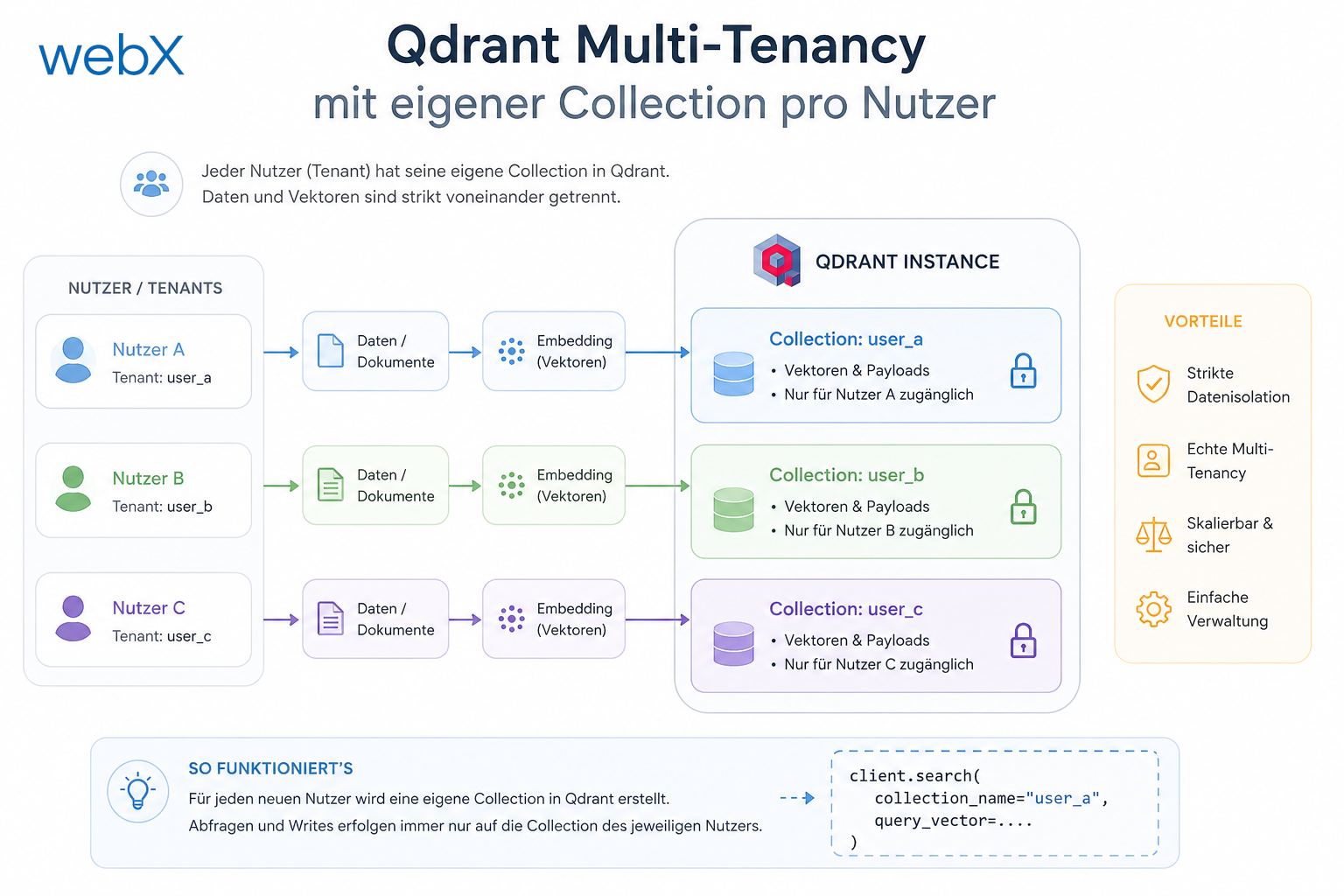
Qdrant Multi-Tenancy mit eigener Collection pro Nutzer
Phase 3 bringt echte Datenisolierung. Jeder Nutzer bekommt eine eigene Qdrant-Collection, einen eigenen S3-Pfad und drei neue Endpunkte für DSGVO-Rechte.
Inhalt
- Warum eine Collection für alle Nutzer das falsche Modell ist
- Dynamische Collection-Namen
- Graceful Returns für neue Nutzer
- S3-Pfade pro Nutzer
- Drei neue DSGVO-Endpunkte
- Ownership-Check beim Capture-Status
- Health-Endpunkt ohne Collection-Name
- Was diese Änderungen in der Praxis bedeuten
- Alle Artikel der Serie
Warum eine Collection für alle Nutzer das falsche Modell ist
Bisher gab es eine einzige Qdrant-Collection: instagram_memory. Das Backend rief beim Start ensureCollection() auf, und danach schrieben und lasen alle Nutzer in denselben Vektorrraum. Das funktioniert für einen einzelnen Nutzer gut, aber es hat drei grundlegende Probleme.
Erstens: Es gibt keine Datenisolierung. Ein Fehler in der Filterschicht könnte dazu führen, dass ein Nutzer die Daten eines anderen sieht. Zweitens: Eine Nutzer-Löschung ist operativ komplex. Die Punkte des gelöschten Nutzers müssen einzeln aus der Collection herausgefiltert und gelöscht werden. Drittens: DSGVO Art. 17 (Recht auf Vergessenwerden) verlangt vollständige Löschbarkeit, und ein deleteAll(filter: userId == X) ist weniger zuverlässig als dropCollection("user_X").
Die Lösung ist einfach: Jeder Nutzer bekommt seine eigene Collection.
Dynamische Collection-Namen
Der Collection-Name wird aus der Zitadel-Sub-Claim des JWT abgeleitet:
function getCollectionName(userId: string): string {
return `user_${userId}_instagram`;
}Zitadel stellt User-IDs im UUID-Format aus, also 550e8400-e29b-41d4-a716-446655440000. Qdrant akzeptiert Bindestriche in Collection-Namen, daher ist keine Normalisierung nötig.
Die Collection wird nicht beim Server-Start angelegt, sondern beim ersten Ingest des jeweiligen Nutzers:
// ingest-worker.ts
const userId = job.data.userId;
await ensureCollection(userId); // creates "user_{userId}_instagram" if not exists
await storePoint(vector, payload, userId);Das ensureCollection prüft zuerst, ob die Collection bereits existiert, und legt sie nur dann an, wenn sie fehlt. Ein einmaliger Netzwerk-Round-Trip pro Job, nicht pro Punkt.
Graceful Returns für neue Nutzer
Das erste Problem, das die Rubber-Duck-Review aufgedeckt hat: Leseoperationen auf einer Collection, die noch nicht existiert, liefern von Qdrant einen Fehler. Ein neuer Nutzer, der noch nichts gespeichert hat, würde beim ersten Aufruf von /query oder /exists eine 500 zurückbekommen.
Die Lösung ist ein Helper, der den Qdrant-Fehler als “leer” interpretiert:
function isCollectionNotFound(err: unknown): boolean {
const msg = err instanceof Error ? err.message : String(err);
return (
msg.includes("Not found") ||
msg.includes("doesn't exist") ||
msg.includes("404") ||
msg.includes("Status: 404")
);
}Qdrant ist in der Formulierung von Fehlermeldungen nicht vollständig konsistent zwischen Versionen, daher werden mehrere Patterns geprüft. Alle Leseoperationen fangen diesen Fehler ab und geben stattdessen ein leeres Ergebnis zurück:
export async function searchSimilar(
vector: number[],
userId: string,
limit: number
): Promise<ScoredPoint[]> {
try {
return await client.search(getCollectionName(userId), { vector, limit });
} catch (err) {
if (isCollectionNotFound(err)) return [];
throw err;
}
}Dasselbe Muster gilt für scrollAllPoints, postIdExists und deleteUserCollections.
S3-Pfade pro Nutzer
Auch der Object Storage war bisher nicht isoliert. Alle Bilder landeten unter posts/{uuid}.png. Mit Phase 3 hat jeder Nutzer seinen eigenen Pfad-Prefix:
export async function uploadImage(
base64: string,
mimeType: string,
userId: string
): Promise<string> {
const extension = mimeType.split("/")[1] ?? "png";
const key = `${userId}/posts/${randomUUID()}.${extension}`;
// ...
}Ein Nutzer hat damit keinen Zugriff auf den Pfad eines anderen Nutzers. Die Löschfunktion kann alle Objekte mit dem Prefix {userId}/ entfernen, ohne eine Liste aller Objekte zu durchsuchen.
Das Löschen läuft paginiert, weil AWS DeleteObjects maximal 1000 Objekte pro Aufruf akzeptiert:
export async function deleteUserBlobs(userId: string): Promise<void> {
let continuationToken: string | undefined;
do {
const list = await s3.send(
new ListObjectsV2Command({
Bucket: BUCKET_NAME,
Prefix: `${userId}/`,
ContinuationToken: continuationToken,
})
);
if (list.Contents?.length) {
await s3.send(
new DeleteObjectsCommand({
Bucket: BUCKET_NAME,
Delete: { Objects: list.Contents.map((o) => ({ Key: o.Key! })) },
})
);
}
continuationToken = list.NextContinuationToken;
} while (continuationToken);
}Drei neue DSGVO-Endpunkte
Phase 3 implementiert die drei datenschutzrechtlich relevanten Nutzeraktionen.
DELETE /account (Art. 17, Recht auf Vergessenwerden): Der Endpunkt löscht in dieser Reihenfolge: ausstehende BullMQ-Jobs, Qdrant-Collection, S3-Blobs und abschließend die Zitadel-Identität. Die Reihenfolge ist bewusst gewählt. Wenn die Qdrant- oder S3-Löschung fehlschlägt, ist die Zitadel-Identität noch vorhanden, und der Nutzer kann erneut versuchen, sein Konto zu löschen.
// Queue cleanup first, before deleting data
const allJobs = await queue.getJobs([
"waiting", "delayed", "active", "completed", "failed"
]);
const userJobs = allJobs.filter((j) => j.data.userId === userId);
await Promise.allSettled(userJobs.map((j) => j.remove()));Die Zitadel-Löschung nutzt die Management API v2 mit einem admin PAT, der als Docker-Volume eingebunden wird:
async function deleteZitadelUser(userId: string): Promise<boolean> {
const pat = await getAdminPat();
const res = await fetch(`${ZITADEL_URL}/v2/users/${userId}`, {
method: "DELETE",
headers: { Authorization: `Bearer ${pat}` },
});
return res.ok;
}GET /account/export (Art. 20, Datenportabilität): Alle Vektorpunkte des Nutzers werden mit scrollAllPoints gelesen und als JSON zurückgegeben. Für jeden Punkt wird eine Presigned URL für das zugehörige Bild generiert, damit der Nutzer seine Daten vollständig exportieren kann.
POST /account/consent: Zeichnet die Einwilligung mit ToS-Version und Timestamp als strukturierter JSON-Eintrag in stdout auf. Das Format ist Grafana/Loki-kompatibel und wird in Phase 5 mit einem Dashboard abgefragt.
console.log(
JSON.stringify({
event: "consent_recorded",
userId,
tosVersion,
consentGivenAt: new Date().toISOString(),
})
);Ownership-Check beim Capture-Status
Der Endpunkt GET /captures/:captureId/status lieferte bisher den Job-Status für jeden, der die Job-ID kannte. Mit Phase 3 wird die Ownership geprüft:
// Only enforce when userId is present (backward compat for old jobs)
if (job.data.userId && job.data.userId !== req.auth!.userId) {
return res.json({ status: "unknown" });
}Alte Jobs ohne userId-Feld werden nicht zurückgewiesen, damit bestehende Daten weiterhin funktionieren.
Health-Endpunkt ohne Collection-Name
Der Health-Endpunkt rief bisher getCollectionInfo("instagram_memory") auf. Diese Collection existiert nach Phase 3 nicht mehr. Der Endpunkt prüft jetzt die Qdrant-Konnektivität auf System-Ebene:
const qdrantResult = await client.getCollections();
const collectionCount = qdrantResult.collections.length;Die Response gibt qdrant.collectionCount zurück statt collection.pointCount. Das Frontend muss diese neue Shape kennen.
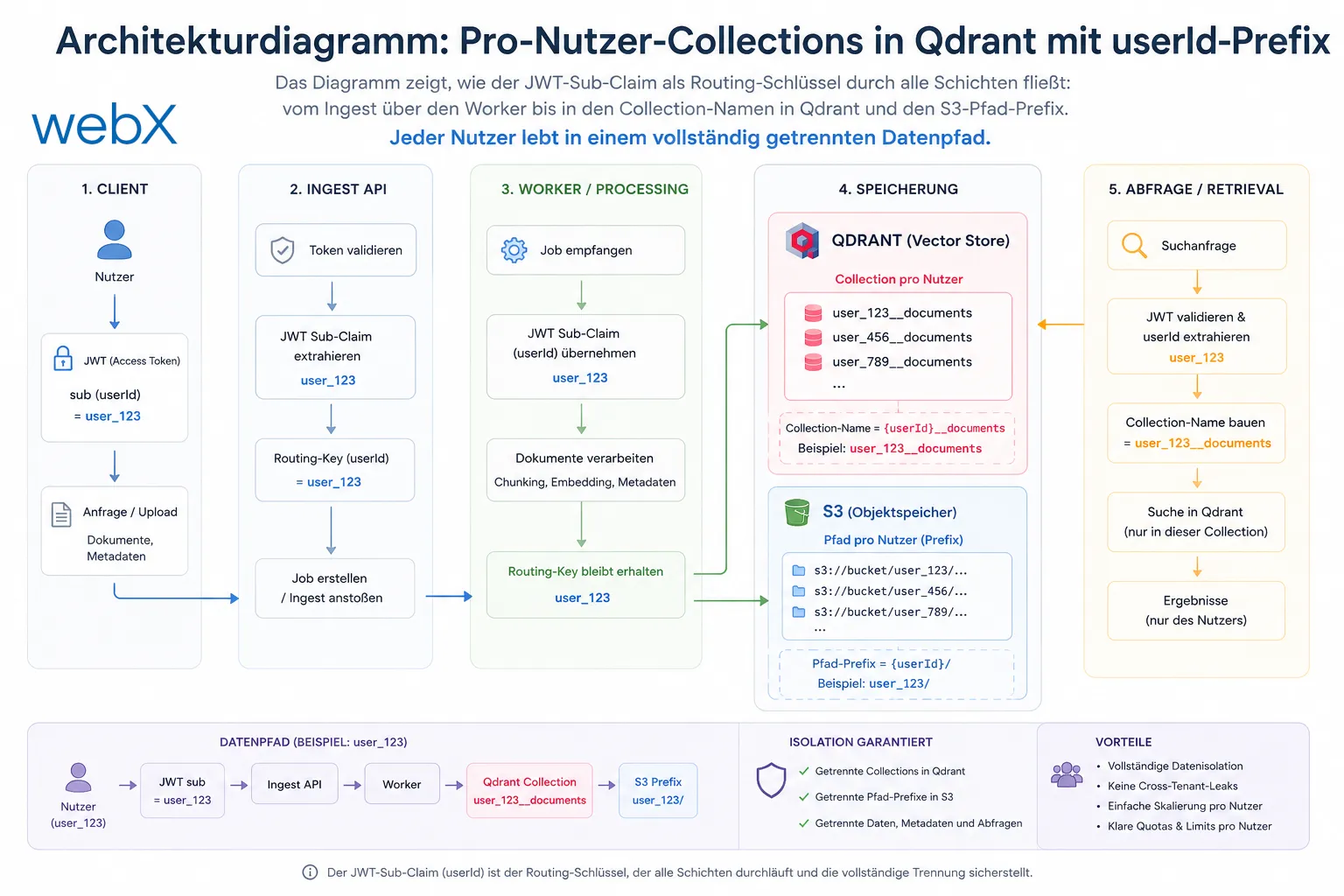
Das Diagramm zeigt, wie der JWT-Sub-Claim als Routing-Schlüssel durch alle Schichten fließt: vom Ingest über den Worker bis in den Collection-Namen in Qdrant und den S3-Pfad-Prefix. Jeder Nutzer lebt in einem vollständig getrennten Datenpfad.
Was diese Änderungen in der Praxis bedeuten
Der TypeScript-Build läuft durch. Der Ingest-Worker erstellt Collections lazy beim ersten Capture. Neue Nutzer erhalten bei Leseanfragen leere Ergebnisse statt Fehler.
Die DSGVO-Anforderungen sind jetzt technisch vollständig implementiert: Löschung, Export und Einwilligungs-Log. Das ist keine kosmetische Maßnahme. Es ist die Grundlage, auf der das System öffentlich betrieben werden kann.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection (dieser Artikel)
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching: Artikel lesen
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
Du baust ein RAG-System mit mehreren Nutzern und DSGVO-Anforderungen? Lass uns das gemeinsam einschätzen.