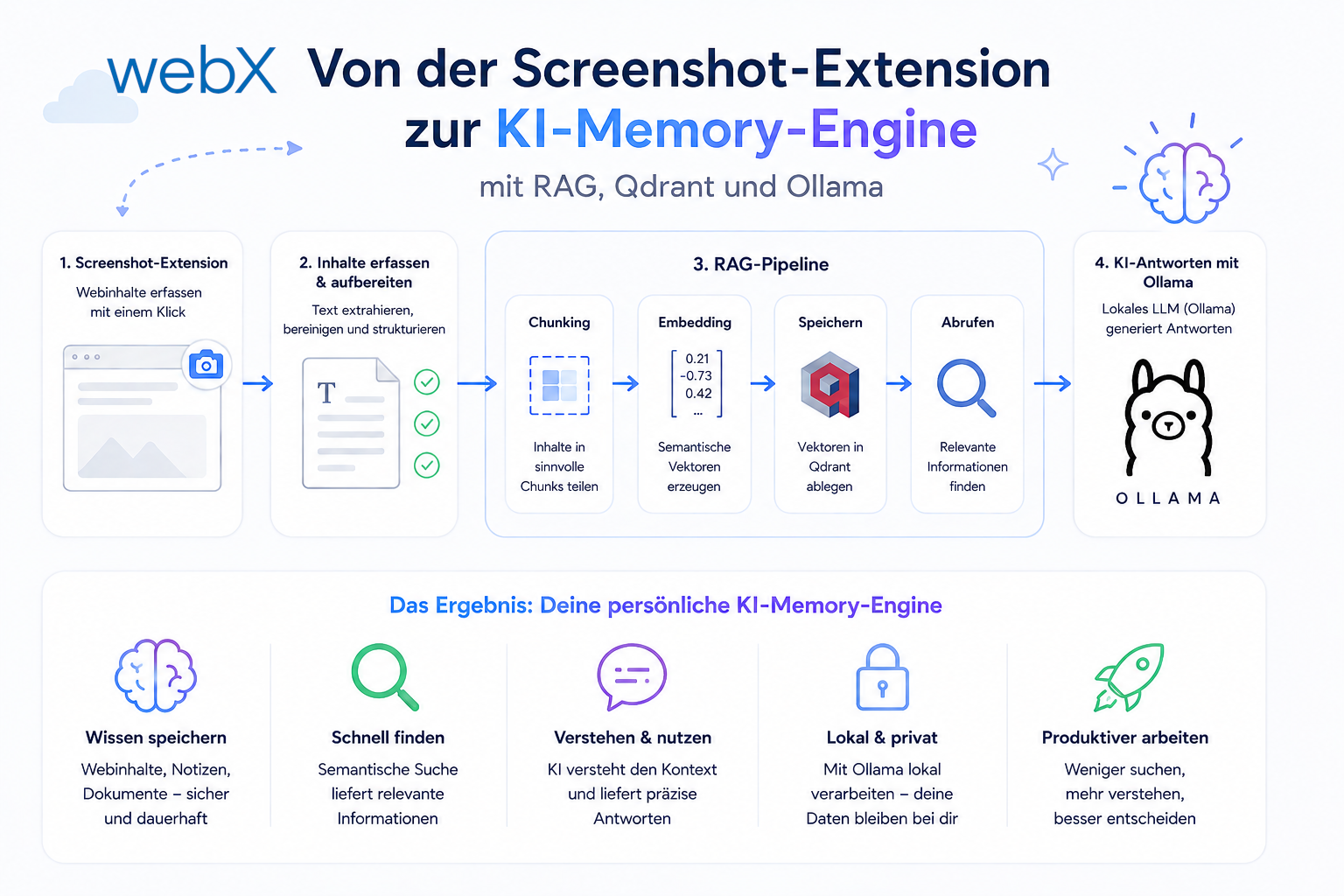
· Architektur · 5 minuten Lesezeit
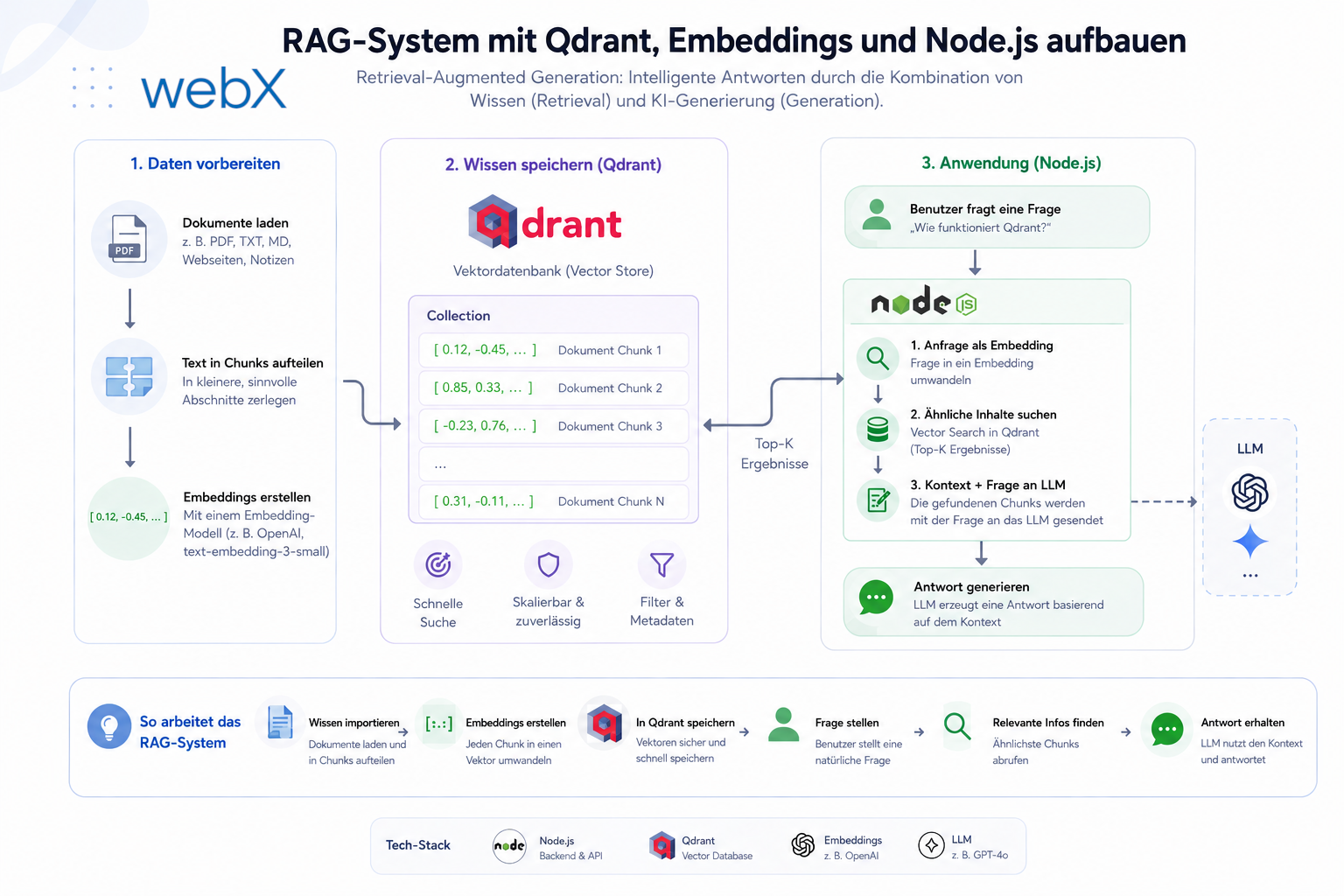
RAG-System mit Qdrant, Embeddings und Node.js aufbauen
Retrieval-Augmented Generation ist keine Theorie. Es ist eine konkrete Architektur aus drei Schritten: Einbetten, Suchen, Generieren. Ich zeige, wie ich das mit Qdrant, nomic-embed-text und llama3.2 komplett lokal und ohne Cloud-Kosten umgesetzt habe.
Inhalt
- Was RAG wirklich bedeutet
- Die Architektur des RAG-Backends
- Was ich über Vektordatenbanken gelernt habe
- Warum das für Power Pages relevant ist
Was RAG wirklich bedeutet
RAG steht für Retrieval-Augmented Generation. Das klingt nach einem Marketingbegriff. Ist es nicht.
Es ist eine Architektur, die ein konkretes Problem löst: LLMs wissen nichts über deine privaten Daten.
ChatGPT weiß nicht, welche Instagram-Posts du letzte Woche erfasst hast. GPT-4o kann nicht auswerten, welche Accounts in den letzten 30 Tagen am häufigsten über ein bestimmtes Thema gepostet haben. Kein Sprachmodell kann das, es sei denn, du gibst ihm den Kontext.
RAG löst das in drei Schritten:
- Einbetten (Embed): Texte werden in hochdimensionale Zahlenvektoren umgewandelt, die semantische Bedeutung kodieren
- Abrufen (Retrieve): Wenn eine Anfrage kommt, wird sie ebenfalls eingebettet und die ähnlichsten gespeicherten Vektoren werden gesucht
- Generieren (Generate): Die gefundenen Texte werden als Kontext an ein LLM übergeben, das daraus eine kohärente Antwort formuliert
Das ist kein Finetuning. Das ist kein Training. Es ist zur Laufzeit injizierter Kontext. Und genau das macht es so praktisch.
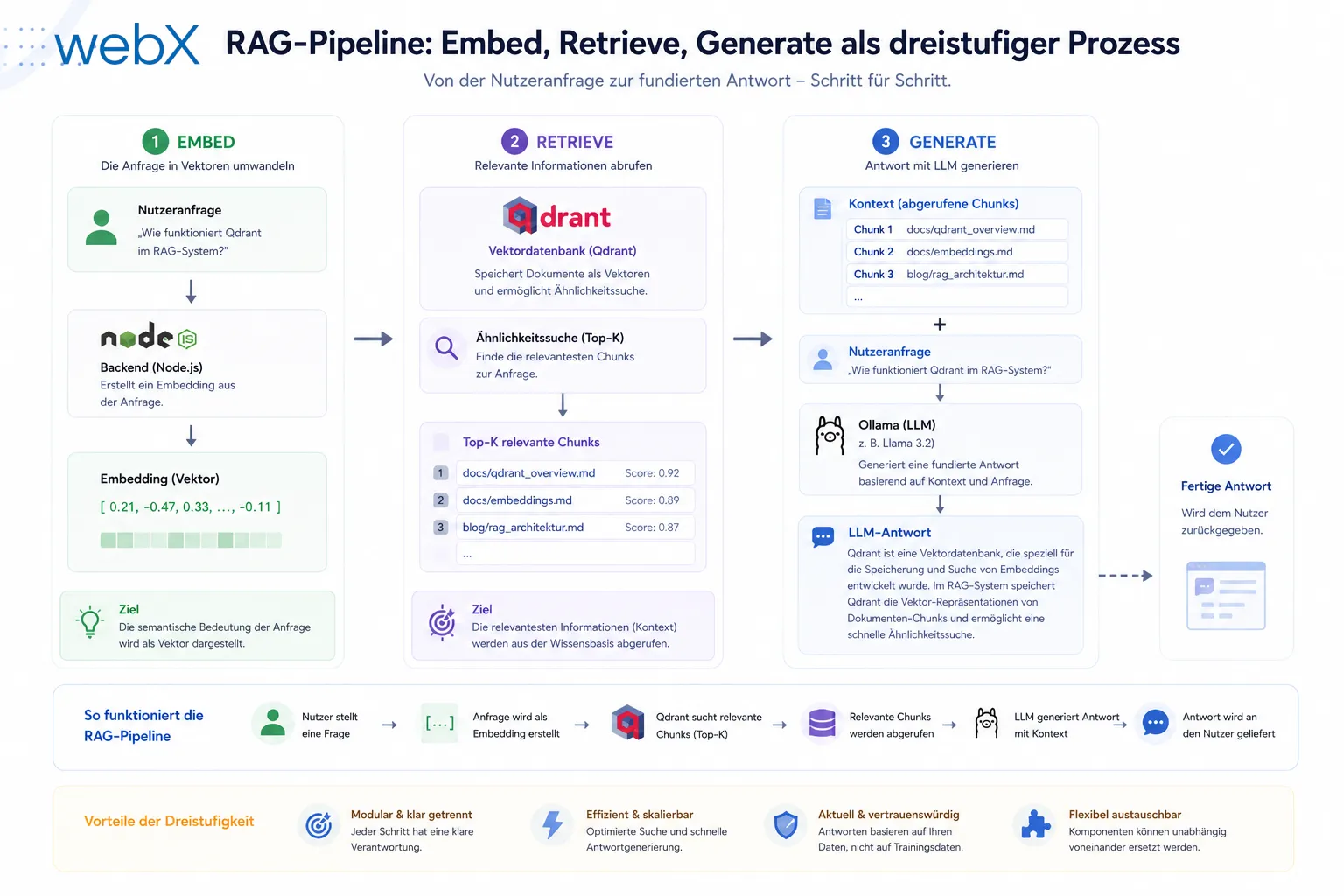
Die drei Schritte im Ablauf: Ein Instagram-Post wird als Text eingebettet und in Qdrant gespeichert. Bei einer Anfrage wird der Fragetext ebenfalls eingebettet, die ähnlichsten Einträge werden abgerufen und als Kontext an das Sprachmodell übergeben.
Die Architektur des RAG-Backends
Das Backend ist ein Node.js/Express-Server in TypeScript. Drei Endpunkte, zwei Services, eine klare Verantwortlichkeit:
src/
├── index.ts # entry point, collection initialization
├── routes/
│ ├── ingest.ts # POST /ingest: store
│ ├── query.ts # POST /query: search + generate
│ └── health.ts # GET /health: status
└── services/
├── qdrant.ts # vector database operations
├── ai-provider.ts # provider abstraction (Ollama | OpenAI)
└── providers/
├── ollama-provider.ts
└── openai-provider.tsVom Instagram-Post zum Vektor
Wenn die Chrome Extension einen Screenshot und Metadaten schickt, passiert folgendes:
// src/routes/ingest.ts
router.post('/', async (req, res) => {
const payload = req.body as PlatformAnalysisPayload;
// 1. Build embedding text from metadata
const embeddingText = buildEmbeddingText(payload);
// result: "some_account Amazing watch #watches Photo of a golden watch"
// 2. Generate vector (768 dimensions)
const vector = await generateEmbedding(embeddingText);
// 3. Store in Qdrant
const id = crypto.randomUUID();
await storePoint(id, vector, payload);
res.status(201).json({ success: true, id, embeddingText });
});Der Text, der eingebettet wird, ist entscheidend. Kombiniert werden:
metadata.username: wer hat gepostet?metadata.caption: was steht dabei?metadata.altTexts.join(" "): was sehen Screenreader?
Alt-Texte sind besonders wertvoll, weil sie oft eine präzise, KI-generierte Bildbeschreibung enthalten, gerade auf Instagram.
Qdrant als Vektordatenbank
Qdrant ist eine speziell für Vektoren optimierte Datenbank. Im Gegensatz zu PostgreSQL mit pgvector oder Elasticsearch ist sie ausschließlich für diesen Anwendungsfall gebaut.
Die Collection wird beim Serverstart automatisch angelegt:
// src/services/qdrant.ts
export async function ensureCollection(): Promise<void> {
const exists = await client.collectionExists(COLLECTION_NAME);
if (!exists) {
await client.createCollection(COLLECTION_NAME, {
vectors: {
size: parseInt(process.env.VECTOR_SIZE ?? '768'),
distance: 'Cosine',
},
});
}
}Warum Cosine-Ähnlichkeit? Bei hochdimensionalen Textvektoren ist die Richtung wichtiger als die absolute Distanz. Cosine misst den Winkel zwischen zwei Vektoren. Zwei Texte, die semantisch ähnlich sind, zeigen in dieselbe Richtung, unabhängig von ihrer Länge. Das ist für Text-Retrieval die richtige Metrik.
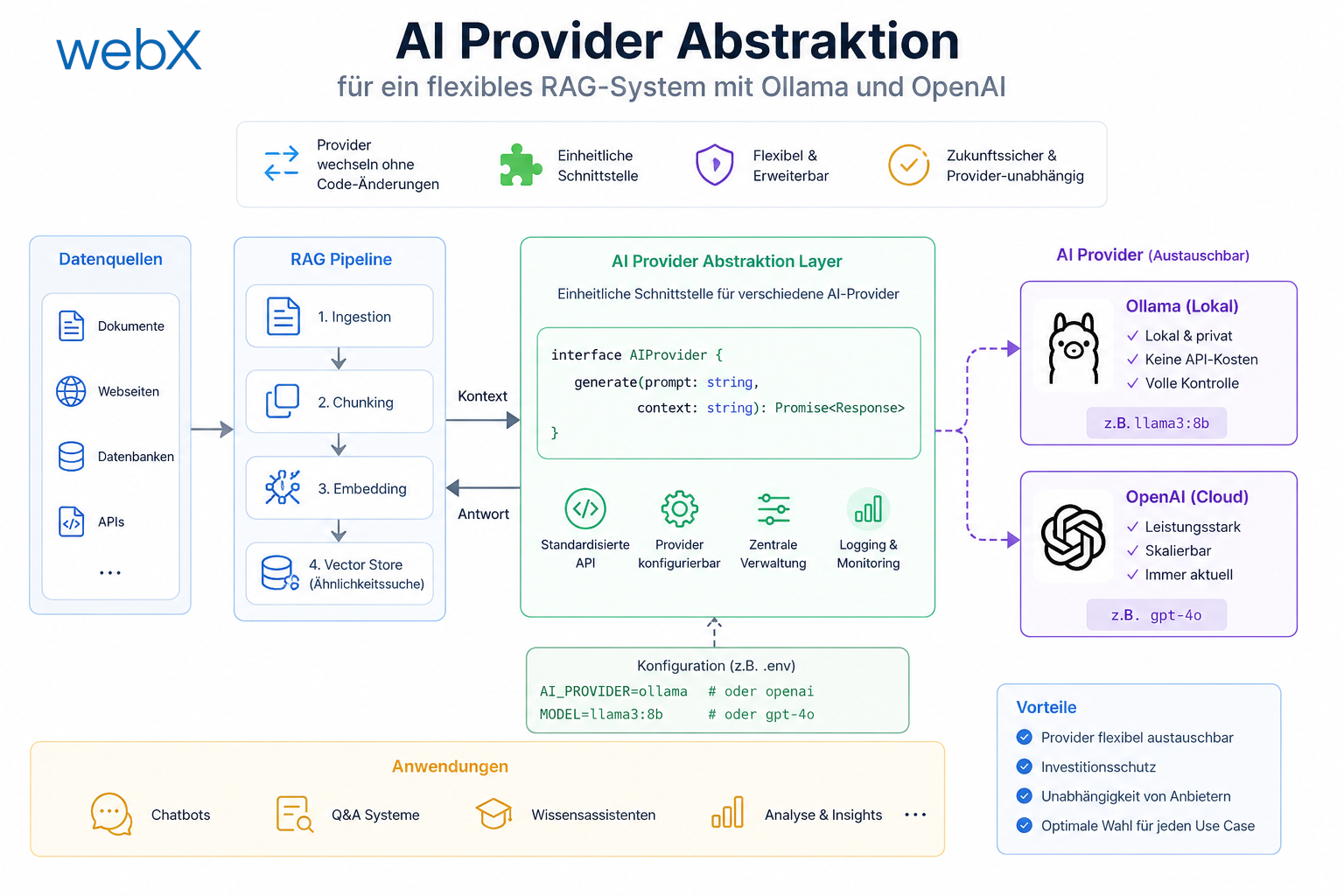
768 Dimensionen: Das ist die Ausgabegröße von nomic-embed-text und von text-embedding-3-small mit dem dimensions-Parameter. Details dazu gibt es im Artikel zur AI Provider Abstraktion.
Suchen und Generieren
// src/routes/query.ts
router.post('/', async (req, res) => {
const { query, limit = 5 } = req.body;
// 1. Embed the query
const queryVector = await generateEmbedding(query);
// 2. Find most similar points in Qdrant
const results = await searchSimilar(queryVector, limit);
// 3. Build context from results
const context = results
.map((r, i) => {
const m = (r.payload as any).metadata;
return `[${i + 1}] @${m.username}: "${m.caption}" (${m.altTexts?.join(', ')})`;
})
.join('\n');
// 4. Generate LLM answer
const answer = await generateAnswer(query, context);
res.json({
answer,
sources: results.map((r) => ({
id: r.id,
score: r.score,
payload: r.payload,
})),
});
});Der Kontext-String, der an das LLM übergeben wird, ist bewusst simpel. Er listet die relevanten Posts mit Username, Caption und Alt-Texten auf. Das Modell hat damit genug Information, um eine präzise Antwort zu generieren.
Das Prompt-Design:
// in ollama-provider.ts
const prompt = `Du bist ein Analyse-Assistent für gespeicherte Social-Media-Posts.
Hier sind die relevanten Einträge aus dem Datenbestand:
${context}
Frage: ${query}
Antworte präzise und auf Basis der obigen Einträge.`;Kein komplexes Chain-of-Thought-Prompting. Für diesen Anwendungsfall reicht es.
 Eine Analyst-Anfrage durchläuft das System: Qdrant liefert die relevantesten gespeicherten Posts als Kontext, Ollama formuliert daraus eine strukturierte Antwort.
Eine Analyst-Anfrage durchläuft das System: Qdrant liefert die relevantesten gespeicherten Posts als Kontext, Ollama formuliert daraus eine strukturierte Antwort.
Was ich über Vektordatenbanken gelernt habe
Vektorgröße ist eine Systementscheidung, keine Modellentscheidung.
Wenn eine Collection einmal mit 768-dimensionalen Vektoren angelegt ist, kann nicht einfach auf ein Modell mit 1536 Dimensionen gewechselt werden, ohne alle Daten neu einzubetten und die Collection neu anzulegen. Das ist der Grund, warum in der Provider-Abstraktion sichergestellt wird, dass beide Modelle (Ollama und OpenAI) exakt 768 Dimensionen produzieren.
OpenAI bietet dafür den dimensions-Parameter in text-embedding-3-small:
const response = await this.client.embeddings.create({
model: 'text-embedding-3-small',
input: text,
dimensions: 768, // explicitly reduced to 768
});Das ist eine strategische Entscheidung: Provider-Wechsel ohne Datenmigration.
Cosine-Ähnlichkeit ist kein prozentualer Score.
Ein Score von 0.91 klingt nach „91% ähnlich”. Das ist nicht korrekt. Es ist der Kosinus des Winkels zwischen zwei Vektoren. Ein Score von 0.7 kann bereits hochrelevant sein. Die absolute Zahl ist weniger wichtig als die relative Rangfolge innerhalb einer Abfrage.
Qdrants JavaScript-Client hat loses Typing.
Das Feld points_count in der Collection-Info ist im TypeScript-Client als any typisiert:
// cast required due to loose typing in Qdrant JS client
const count = (collectionInfo as any).points_count as number;Kein schöner Code, aber wer mit externen Clients arbeitet, muss mit solchen Inkonsistenzen umgehen können.
Warum das für Power Pages relevant ist
Viele Power Pages Portale verwalten große Mengen an Dokumenten, FAQs, Produktbeschreibungen oder Support-Tickets in Dataverse. Die klassische Suche ist keyword-basiert und findet nur exakte Treffer.
Semantische Suche auf Basis von RAG würde ermöglichen:
- „Welche Produkte haben ähnliche Eigenschaften wie dieser Artikel?”
- „Finde alle Support-Tickets, die mit diesem Problem zusammenhängen”
- „Welche FAQ-Einträge sind für diese Anfrage relevant?”
Die Technologie dafür ist dieselbe. Der Stack wäre identisch. Was sich ändert, ist nur die Datenquelle (Dataverse statt Instagram) und die Einbettungslogik.
Nächster Artikel in der Serie: Die Entscheidung, die alles verändert hat: Provider-Abstraktion für Ollama und OpenAI
Du willst semantische Suche in ein Power Pages Portal einbauen, ohne auf AI Builder oder Copilot Studio angewiesen zu sein? Lass uns den Use Case gemeinsam durchdenken.