· Webentwicklung · 6 minuten Lesezeit
Instagram PostId aus Feed und Kanal-Grid korrekt extrahieren
Instagram nutzt im Feed article-Tags, im Kanal-Grid nicht. ancestor traversal löst falsche PostIds, eine Promise-Map verhindert doppelte Backend-Requests.
Inhalt
- Das Problem mit zwei Instagram-Layouts
- Warum
querySelectorim falschen Container gefährlich ist - Die zwei Strategien
- Doppelte Requests durch gleichzeitige Events
- Was das über DOM-Traversal-Entscheidungen aussagt
- Alle Artikel der Serie
Das Problem mit zwei Instagram-Layouts
Instagram rendert Posts nicht überall gleich. Auf der Startseite und im Feed ist jeder Post in einem <article>-Element eingebettet. Auf einer Kanal-Profilseite, also wenn du ein bestimmtes Konto aufrufst, erscheinen die Posts als Grid-Thumbnails ohne <article>.
Das ist kein Edge Case. Das ist eine fundamentale Layoutentscheidung von Instagram, und sie hat direkte Konsequenzen für jede Extension, die mit PostIds arbeitet.
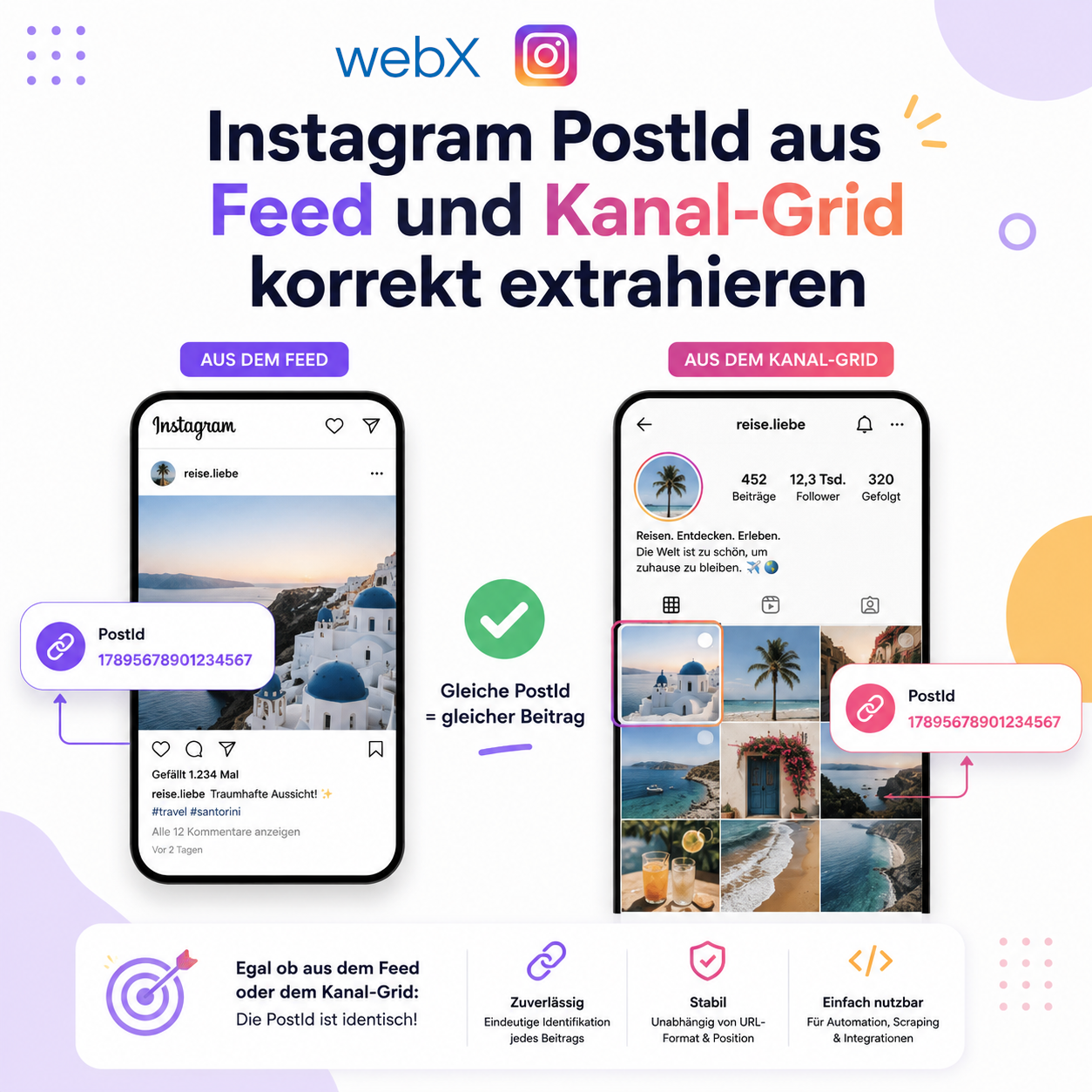
 Abbildung: Die zwei Instagram-Layouts im Vergleich. Links der Feed mit article-Wrapper um jeden einzelnen Post. Rechts das Kanal-Grid ohne article, nur verschachtelte Divs mit einem a-Tag als äußerem Wrapper.
Abbildung: Die zwei Instagram-Layouts im Vergleich. Links der Feed mit article-Wrapper um jeden einzelnen Post. Rechts das Kanal-Grid ohne article, nur verschachtelte Divs mit einem a-Tag als äußerem Wrapper.
Die Duplikatserkennung aus Phase 2 basiert darauf, beim Hover eine PostId aus dem DOM zu extrahieren und das Backend zu fragen, ob dieser Post bereits gespeichert ist. Auf der Feed-Seite hat das funktioniert. Auf Kanal-Profilseiten zeigte die Extension immer eine rote Umrandung, egal ob der Post neu war oder nicht.
Warum querySelector im falschen Container gefährlich ist
Die ursprüngliche Extraktion war so aufgebaut:
const article = findArticleElement(element);
const postId = article ? quickExtractPostId(article) : null;findArticleElement traversiert vom gerade gehoverten Element aufwärts und sucht ein <article>-Tag. Auf der Feed-Seite findet es eins. Auf der Kanal-Profilseite nicht.
Der Fehler war, dass bei fehlendem <article> einfach null zurückgegeben wurde. Kein <article>, keine PostId, rote Umrandung. Technisch korrekt, aber nicht das Ziel.
Nach der ersten Behebung entstand ein subtileres Problem. Ich hatte quickExtractPostId so geändert, dass es auch ohne <article> funktioniert, indem querySelector auf dem gerade gehoverten Element aufgerufen wird.
Das führte zu doppelten Backend-Calls mit zwei verschiedenen PostIds.
Der Grund: querySelector durchsucht alle Nachkommen. Wenn event.target ein Container-Div ist, der mehrere Post-Zellen umschließt, findet querySelector('a[href*="/p/"]') den ersten <a>-Link in diesem gesamten Container. Der gehört möglicherweise einem anderen Post als dem, über dem die Maus gerade liegt.
Ein Beispiel: Der Cursor ist über einem äußeren Wrapper-Div. querySelector läuft durch alle Kinder dieses Divs und gibt den Link von Post Nummer 3 zurück, obwohl der Cursor über Post Nummer 7 liegt.
Die zwei Strategien
Die saubere Lösung ist eine klare Trennung nach Layout.
Strategie 1 für Feed/Landing (quickExtractPostId)
Hier ist querySelector sicher, weil jedes <article> genau einen Post umschließt. Ein descendant-Search innerhalb eines <article> kann niemals einen Link eines anderen Posts zurückgeben.
const quickExtractPostId = (article: HTMLElement): string | null => {
const link =
article.querySelector<HTMLAnchorElement>('a[href*="/p/"]') ||
article.querySelector<HTMLAnchorElement>('a[href*="/reel/"]');
if (!link) return null;
const match = link.getAttribute('href')?.match(/\/(p|reel)\/([^/]+)/);
return match ? match[2] : null;
};Aufgerufen mit dem gefundenen <article>. Sicher. Deterministisch.
Strategie 2 für Kanal-Grid (quickExtractPostIdFromAncestor)
Auf der Kanal-Profilseite sieht die DOM-Struktur so aus:
<div>
<!-- äußerer Wrapper -->
<a href="/businessinsider/p/DYck-9TFw40/">
<!-- ← PostId steckt hier -->
<div>
<div><img … /></div>
<!-- ← das gehoverte Element -->
<div></div>
<!-- leerer Div -->
</div>
<div></div>
<!-- leerer Div -->
</a>
</div>Das gehoverte Element ist das <img>. Der <a>-Link mit der PostId ist ein Vorfahren-Element, kein Nachfahre. querySelector schaut nach unten. Hier muss nach oben traversiert werden.
const quickExtractPostIdFromAncestor = (element: HTMLElement): string | null => {
let current: HTMLElement | null = element;
while (current && current !== document.body) {
if (current.tagName.toLowerCase() === 'a') {
const href = current.getAttribute('href') ?? '';
const match = href.match(/\/(p|reel)\/([^/]+)/);
if (match) return match[2];
}
// Empty divs mark the boundary between grid cells
if (
current !== element &&
current.tagName.toLowerCase() === 'div' &&
current.children.length === 0 &&
!current.textContent?.trim()
) {
break;
}
current = current.parentElement;
}
return null;
};Ancestor-Traversal geht ausschließlich nach oben. Sie kann nie in einen Nachbar-Post hineinlaufen. Die Stoppbedingung bei leeren Divs verhindert, dass die Traversal über die strukturelle Grenze einer Grid-Zelle hinausläuft.
 Abbildung: Traversal-Pfad im Kanal-Grid. Gestartet wird beim gehoverten img. Der Algorithmus läuft aufwärts, bis entweder ein a-Tag mit PostId-href gefunden wird oder ein leerer div die Grenze zur nächsten Grid-Zelle markiert.
Abbildung: Traversal-Pfad im Kanal-Grid. Gestartet wird beim gehoverten img. Der Algorithmus läuft aufwärts, bis entweder ein a-Tag mit PostId-href gefunden wird oder ein leerer div die Grenze zur nächsten Grid-Zelle markiert.
Im mouseover-Handler wird jetzt explizit verzweigt:
const article = findArticleElement(element);
const postId = article
? quickExtractPostId(article) // Feed/Landing: safe because of <article> boundary
: quickExtractPostIdFromAncestor(element); // Channel grid: traverse upwardsDoppelte Requests durch gleichzeitige Events
Nach dem Fix der falschen PostIds blieb ein weiteres Problem: Für denselben Post wurden zwei identische Backend-Requests gesendet.
Der Grund ist, wie mouseover in Browsern funktioniert. Wenn die Maus über ein <img> fährt, feuert mouseover für das <img> und für alle Eltern-Elemente, die das Event empfangen. In wenigen Millisekunden kann dasselbe mouseover-Handler-Event mehrfach für verschiedene DOM-Elemente ausgeführt werden, die alle dieselbe PostId auflösen.
Ein Cache auf Basis der letzten gespeicherten PostId hilft nur, wenn ein Request bereits abgeschlossen ist. Bei gleichzeitigen Aufrufen sehen beide denselben leeren Cache und schicken beide einen Request.
Die Lösung ist eine In-Flight-Deduplizierungs-Map:
const pendingColourChecks = new Map<string, Promise<string>>();
const resolveHighlightColour = (postId: string): Promise<string> => {
if (postId === lastCheckedPostId) return Promise.resolve(lastCheckedColour);
// Request for this postId already in flight: return the same promise
const inflight = pendingColourChecks.get(postId);
if (inflight) return inflight;
const promise = chrome.runtime
.sendMessage({ action: 'check-duplicate', postId })
.then((response) => {
const colour = response?.exists ? COLOUR_DUPLICATE : COLOUR_NEW;
lastCheckedPostId = postId;
lastCheckedColour = colour;
return colour;
})
.catch(() => COLOUR_DEFAULT)
.finally(() => pendingColourChecks.delete(postId)); // ← clean up after completion
pendingColourChecks.set(postId, promise);
return promise;
};Wenn zwei mouseover-Events gleichzeitig dieselbe PostId anfordern, teilen sie sich eine einzige Promise. Der zweite Aufrufer wartet auf das Ergebnis des ersten, ohne einen eigenen Backend-Request auszulösen.
Zwei Caching-Ebenen, jede für einen anderen Zeitpunkt:
| Ebene | Zeitpunkt | Mechanismus |
|---|---|---|
lastCheckedPostId | Nach abgeschlossenem Request | Einfacher String-Vergleich |
pendingColourChecks | Während laufendem Request | Map<string, Promise<string>> |
Was das über DOM-Traversal-Entscheidungen aussagt
Die zentrale Erkenntnis aus diesem Debugging-Prozess: querySelector und querySelectorAll sind keine allgemeinen Lösungen. Sie funktionieren, wenn du weißt, dass der Container genau einen semantischen Bereich repräsentiert. Auf einem Feed mit <article>-Elementen ist das gegeben. In einem Grid-Layout ohne semantische Container ist es das nicht.
Wer DOM-Traversal in dynamischen Webseiten macht, sollte immer folgende Frage beantworten: Kann mein Such-Container mehrere gleichartige Elemente enthalten? Wenn ja, ist ein descendant-Search unpräzise. Ancestor-Traversal ist in solchen Fällen die zuverlässigere Strategie, weil sie ausschließlich nach oben läuft und damit keine unbeabsichtigten Treffer erzeugen kann.
Und für alle gleichzeitigen asynchronen Anfragen auf dasselbe Datum gilt: Eine Map<key, Promise> ist das einfachste und zuverlässigste Mittel gegen doppelte Requests, das ich kenne.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
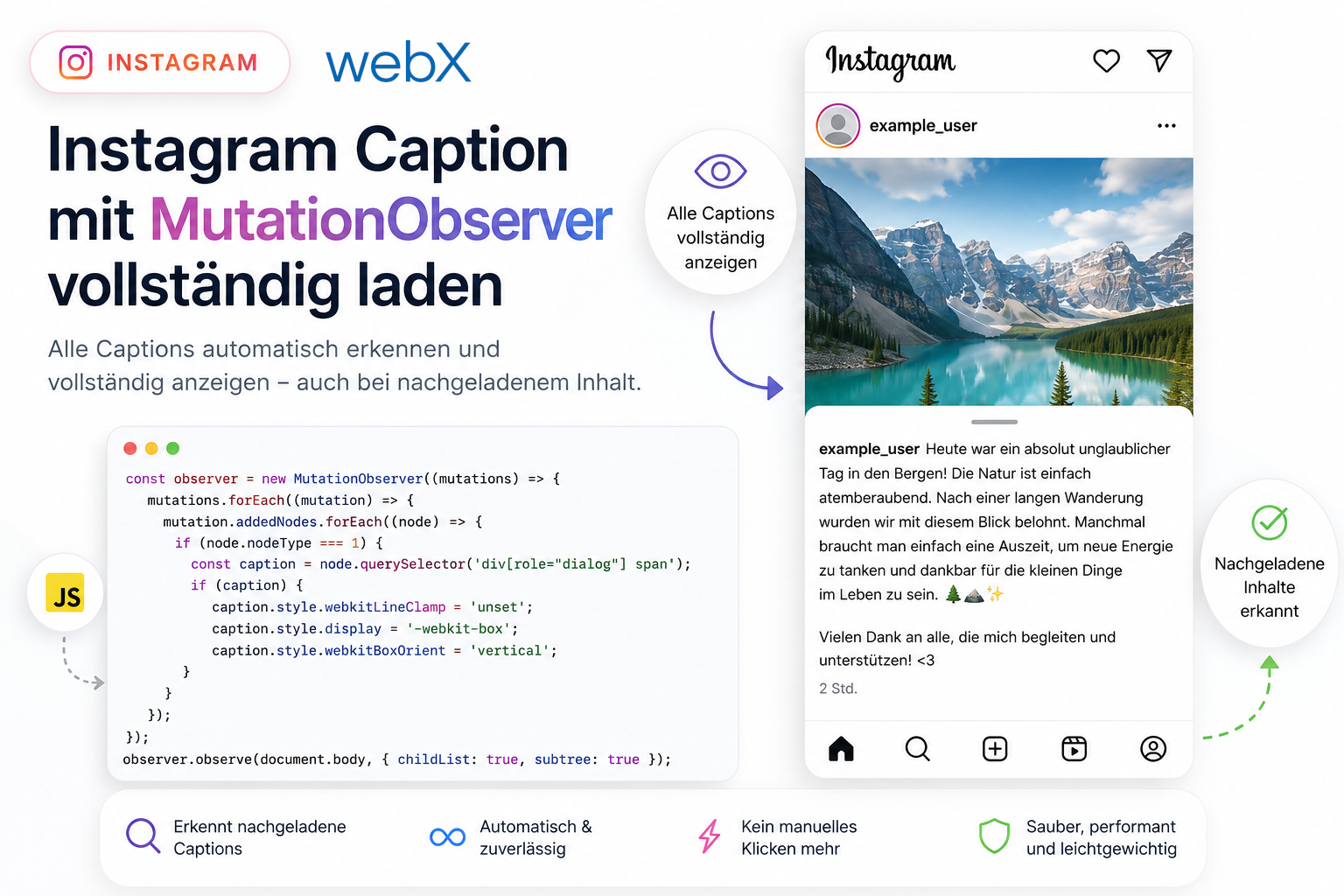
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
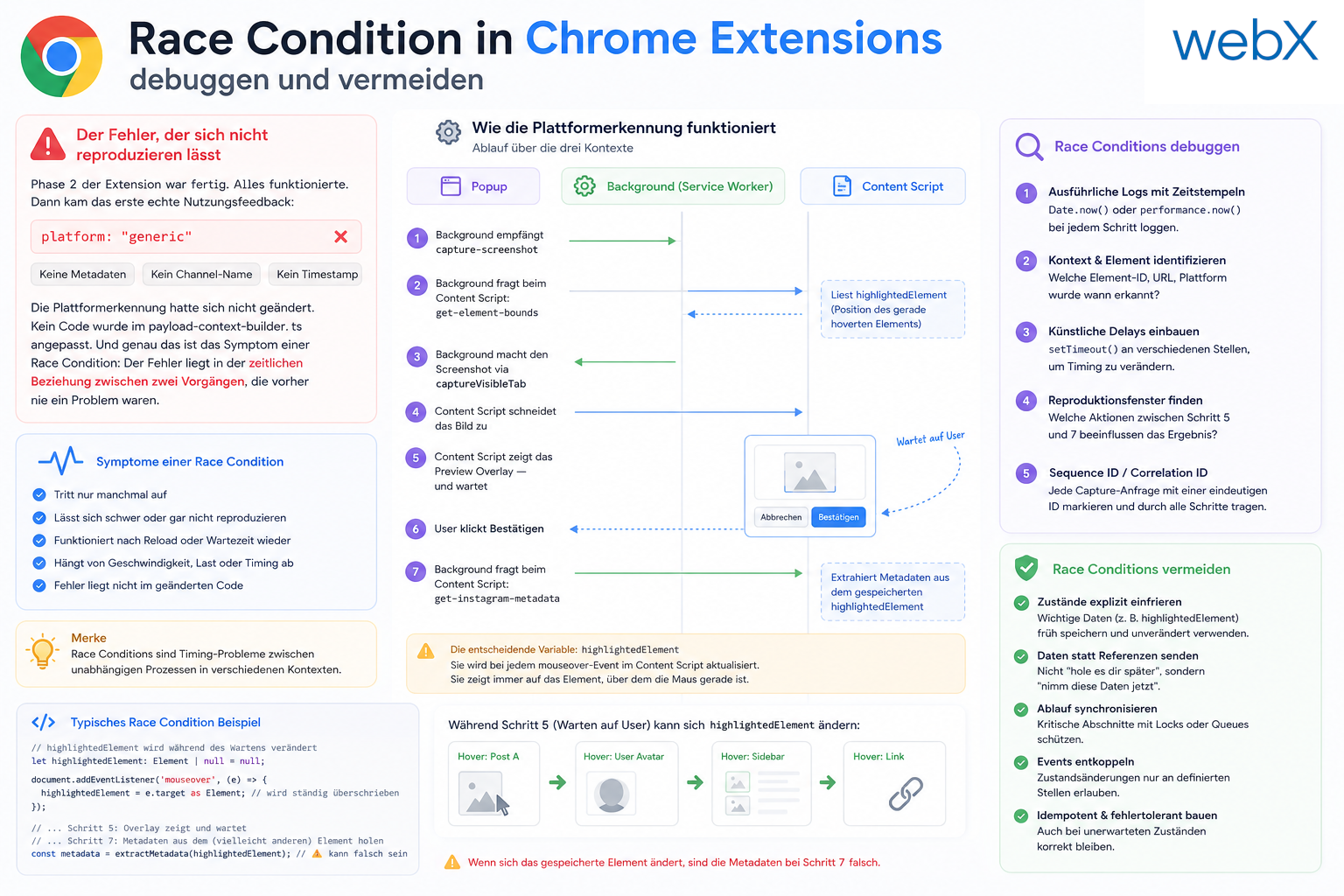
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal (dieser Artikel)
Du arbeitest an DOM-Extraktion in komplexen SPAs oder baust ein Monitoring-Tool auf Basis von Browser Extensions? Lass uns das gemeinsam einschätzen.