· Backend · 6 minuten Lesezeit
DSGVO Art. 17 korrekt implementieren mit Promise.allSettled und Export-Batching
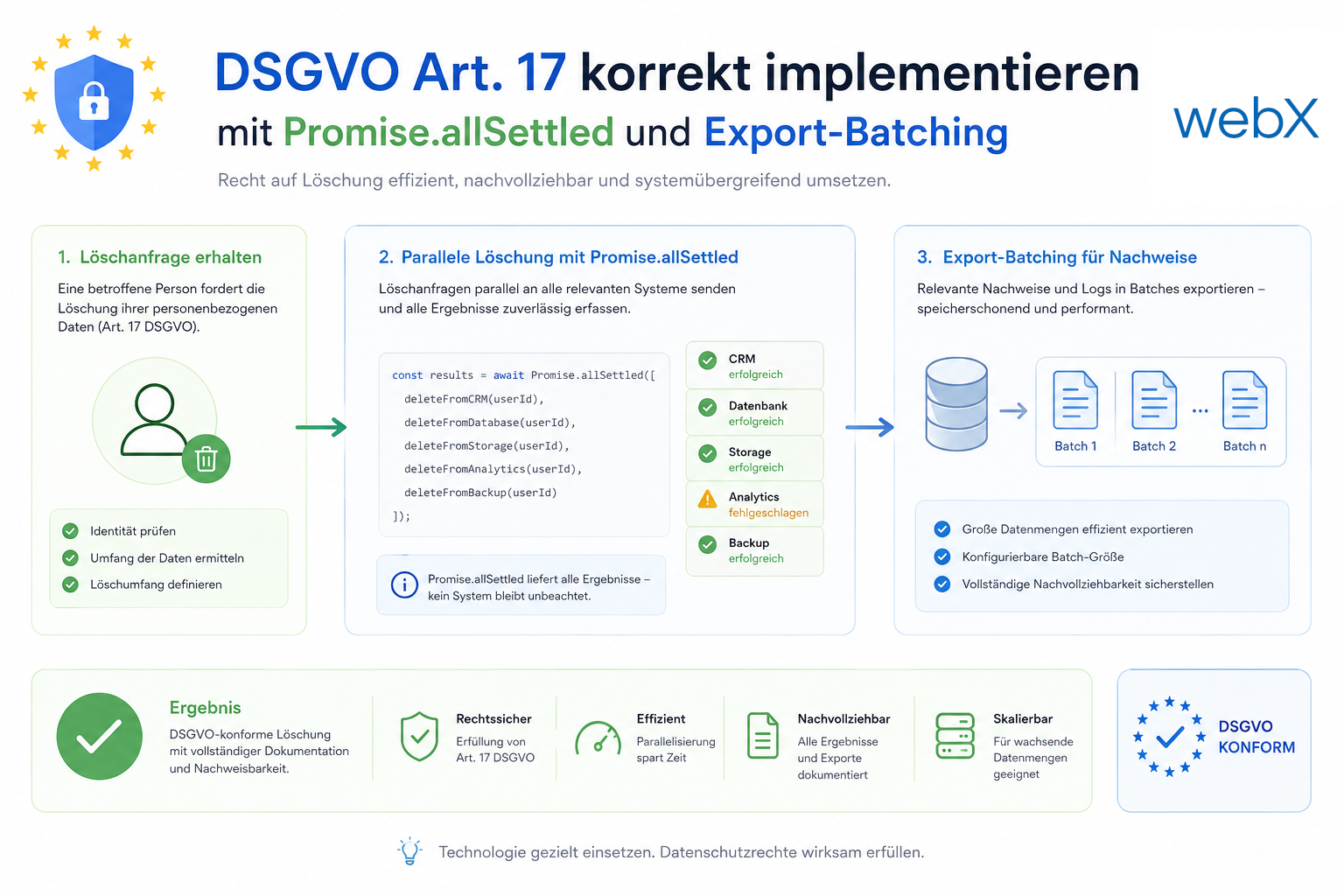
Ein sequenzielles await-chain im DELETE-Account-Endpoint bedeutet: wenn Qdrant fehlschlägt, bleiben S3-Daten und die Zitadel-Identität erhalten. Das ist ein DSGVO-Art.-17-Risiko. Die Lösung ist Promise.allSettled mit strukturierter Fehlerrückgabe. Gleichzeitig: wie ein OOM-Crash im Export-Endpoint durch Batching verhindert wird.
Inhalt
- Das Problem mit sequenziellem await
- Promise.allSettled als Lösung
- HTTP 207 als korrekter Statuscode
- Das OOM-Problem beim Export
- Batching als Lösung
- Was diese zwei Fixes gemeinsam haben
- Alle Artikel der Serie
Das Problem mit sequenziellem await
Der DELETE /account-Endpoint löscht alle Daten eines Nutzers: BullMQ-Jobs, Qdrant-Collections, S3-Blobs und die Zitadel-Identität. Das ist DSGVO Art. 17, das Recht auf Löschung.
Der ursprüngliche Code sah so aus:
// Original: sequential await chain — first failure stops all remaining steps
router.delete("/", authMiddleware, async (req, res) => {
const { userId } = req.auth;
try {
await deleteUserJobs(userId);
await deleteUserCollections(userId);
await deleteUserBlobs(userId);
await deleteZitadelUser(userId);
res.status(204).send();
} catch (err) {
res.status(500).json({ error: "Deletion failed" });
}
});Das sieht sauber aus, hat aber ein strukturelles Problem: Wenn deleteUserCollections fehlschlägt (zum Beispiel weil Qdrant kurz nicht erreichbar ist), werden deleteUserBlobs und deleteZitadelUser nie aufgerufen. Die Qdrant-Daten fehlen, aber S3-Blobs und die Zitadel-Identität bleiben erhalten.
Für Art. 17 bedeutet das: Unter Last oder bei kurzen Infrastrukturfehlern bleibt eine Löschanfrage still unvollständig. Der Nutzer bekommt einen 500-Fehler, aber keine Information, was gelöscht wurde und was nicht.
Promise.allSettled als Lösung
Promise.allSettled führt alle Promises parallel aus und gibt für jedes Promise einzeln an, ob es erfüllt oder abgelehnt wurde. Es bricht nicht ab, wenn ein Promise fehlschlägt.
Das ist genau das richtige Werkzeug für diesen Fall: Alle vier Löschschritte sollen immer ausgeführt werden, unabhängig davon, was bei den anderen passiert.
router.delete("/", authMiddleware, async (req, res) => {
const { userId } = (req as AuthenticatedRequest).auth;
const steps = [
{ name: "bullmq", fn: () => deleteUserJobs(userId) },
{ name: "qdrant", fn: () => deleteUserCollections(userId) },
{ name: "s3", fn: () => deleteUserBlobs(userId) },
{ name: "zitadel", fn: () => deleteZitadelUser(userId) },
];
const results = await Promise.allSettled(steps.map((s) => s.fn()));
const failed = steps
.map((s, i) => ({ name: s.name, result: results[i] }))
.filter((s) => s.result.status === "rejected")
.map((s) => ({
store: s.name,
// Capture rejection reason for logging and response
reason: s.result.status === "rejected" ? String(s.result.reason) : "",
}));
if (failed.length > 0) {
logger.error({ userId, failed }, "Partial account deletion failure");
// HTTP 207: some steps succeeded, some failed
return res.status(207).json({
deleted: steps.length - failed.length,
failed,
});
}
res.status(204).send();
});Mit Promise.allSettled gilt: Alle vier Schritte laufen immer. Wenn BullMQ oder Qdrant nicht erreichbar sind, laufen S3 und Zitadel trotzdem. Das ist idempotent-freundlich: Der Nutzer kann die Anfrage wiederholen, und die bereits gelöschten Stores werden beim zweiten Versuch einfach mit einem Nicht-Fehler quittieren.
HTTP 207 als korrekter Statuscode
Bei partiellen Fehlern gibt der Endpoint HTTP 207 zurück, nicht 500.
500 würde signalisieren: “Ich weiß nicht, was passiert ist.” 207 ist der korrekte Code für “Multi-Status”: Einige Operationen haben funktioniert, andere nicht. Der Response-Body listet, was gescheitert ist:
{
"deleted": 3,
"failed": [
{ "store": "qdrant", "reason": "connect ECONNREFUSED 127.0.0.1:6333" }
]
}Die Extension und das Frontend können diesen Response verarbeiten und dem Nutzer eine sinnvolle Meldung zeigen, statt ihn mit einem generischen Fehler stehen zu lassen.
Das OOM-Problem beim Export
GET /account/export lädt alle gespeicherten Screenshots eines Nutzers und gibt für jeden einen presigned S3-URL zurück. Der ursprüngliche Code:
// Original: all presigns generated concurrently — OOM at scale
const points = await scrollAllPoints(userId);
const records = await Promise.all(
points.map((p) => getPresignedUrl(p.payload.image.blobName))
);scrollAllPoints paginiert intern in Batches von 100, das ist korrekt. Das Problem liegt in Promise.all(points.map(...)): Wenn ein Nutzer 1.000 Screenshots hat, werden 1.000 S3-Presign-Requests gleichzeitig gefeuert. Jeder Presign-Request hält einen offenen HTTP-Client-State im Speicher.
Bei tausend Requests passieren zwei Dinge gleichzeitig: Der Heap wächst bis zum OOM-Kill, und AWS SDK wirft Rate-Limit-Fehler, weil zu viele parallele Verbindungen aufgebaut werden.
Batching als Lösung
Die Lösung ist eine sequenzielle Batch-Verarbeitung mit fester Batch-Größe:
const points = await scrollAllPoints(userId);
const records: ExportRecord[] = [];
// Process presigns in batches of 50 to prevent OOM and S3 rate limits
for (let i = 0; i < points.length; i += 50) {
const batch = points.slice(i, i + 50);
const batchRecords = await Promise.all(
batch.map(async (p) => ({
capturedAt: p.payload.capturedAt,
platform: p.payload.platform,
url: await getPresignedUrl(p.payload.image.blobName),
tags: p.payload.tags ?? [],
note: p.payload.note ?? "",
}))
);
records.push(...batchRecords);
}
res.json({ records });Innerhalb jedes Batches laufen 50 Requests parallel. Zwischen den Batches ist der Heap wieder frei. Der Response-Zeitraum steigt bei sehr vielen Captures (1.000 Captures: 20 Batches à 50, jeder Batch dauert ca. 100ms bedeutet grob 2 Sekunden), aber es gibt kein OOM-Risiko.
Das Format der Antwort ändert sich nicht. Nur der interne Verarbeitungspfad ist anders.
Was diese zwei Fixes gemeinsam haben
Beide Probleme kommen vom selben Denkmuster: “Happy Path zuerst, Fehler werden schon nicht vorkommen.”
Bei DELETE war die Annahme: Alle Stores sind immer erreichbar. Bei Export war die Annahme: Nutzer haben keine große Datenmenge.
Beide Annahmen stimmen in Entwicklung. In Produktion mit echten Nutzern und echten Fehlerraten stimmen sie nicht mehr. Infrastruktur ist flaky, Nutzer akkumulieren Daten.
DSGVO Art. 17 und Art. 20 (Datenportabilität) setzen voraus, dass diese Endpunkte unter realen Bedingungen korrekt funktionieren. Das war vor diesen Fixes nicht garantiert.
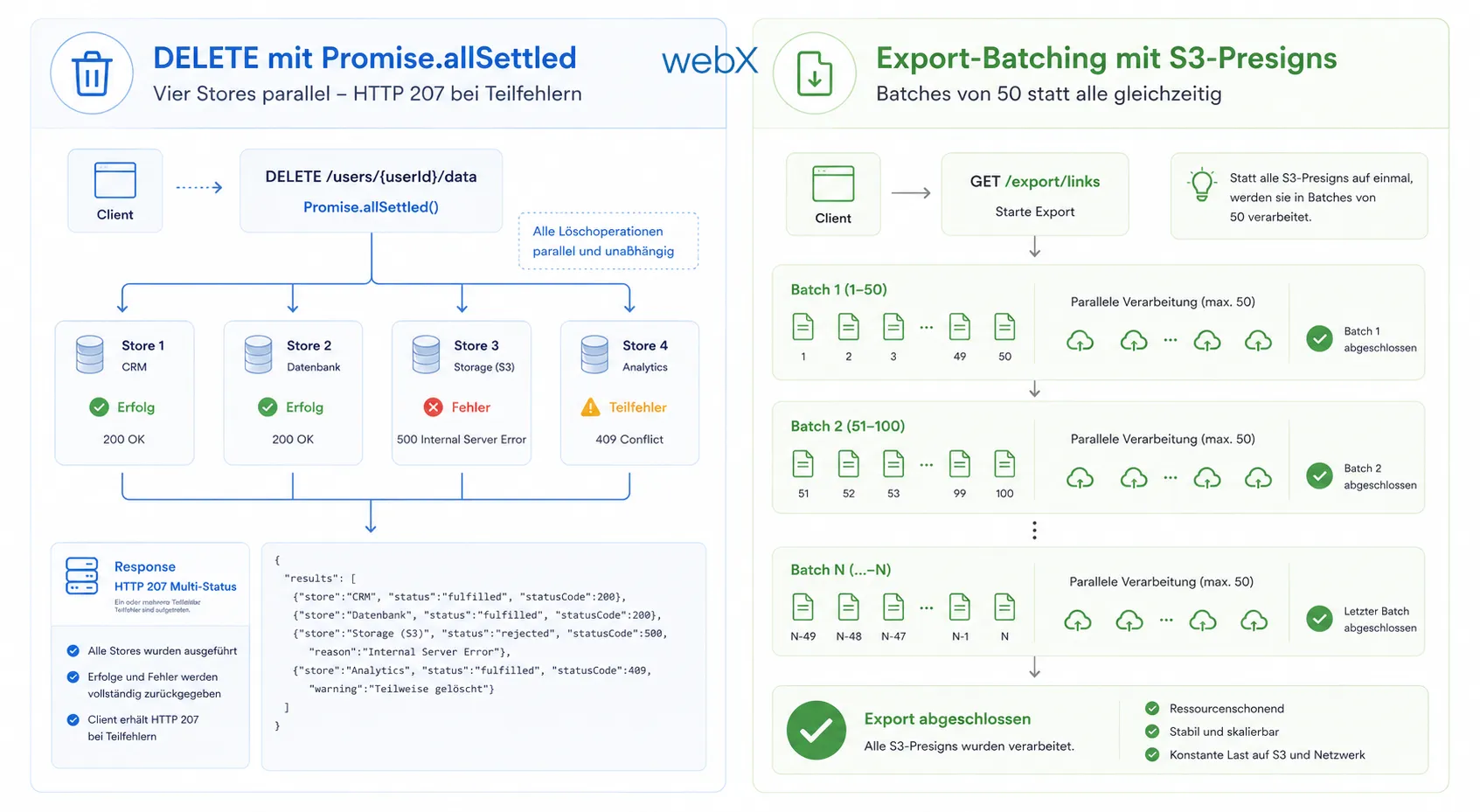
Links zeigt der DELETE-Pfad vier parallele Löschoperationen mit Promise.allSettled. Jede Operation läuft unabhängig, Teilfehler werden im Response dokumentiert. Rechts zeigt der Export-Pfad die sequenzielle Batch-Schleife: 50 Presigns gleichzeitig, dann der nächste Batch, bis alle Punkte verarbeitet sind.
Alle Artikel der Serie
- Vision und Systemübersicht: Chrome Extension, RAG-Architektur, Projekthintergrund: Artikel lesen
- RAG-System Aufbau: Qdrant, Embeddings, Cosine-Ähnlichkeit in TypeScript: Artikel lesen
- AI Provider Abstraktion: Ollama vs. OpenAI, Interface-Design, kein Vendor-Lock-in: Artikel lesen
- Chrome Extension MV3: Drei isolierte Laufzeitkontexte, Message Passing, Strategy Pattern: Artikel lesen
- Docker Compose Strategie: Override-Pattern, von lokal zu Azure: Artikel lesen
- Ollama lokal vs. Docker: Die Entscheidung und ihre Konsequenzen: Artikel lesen
- Ollama Auto-Pull Entrypoint: Automatisiertes Modell-Setup beim Container-Start: Artikel lesen
- tsconfig und Vite:
Node16vs.bundler, warum Vite eigene Regeln hat: Artikel lesen - Instagram Caption mit MutationObserver vollständig laden: Artikel lesen
- Chrome Extension Foundation mit Health-Dot und Retry-Queue: Artikel lesen
- Phase 2 Features: Shadow DOM Overlay, Tailwind v4, Duplicate Detection: Artikel lesen
- Race Condition bei der Plattformerkennung: Wie ein UI-Event die Instagram-Erkennung bricht: Artikel lesen
- PostId-Extraktion in zwei Instagram-Layouts: querySelector vs. Ancestor-Traversal: Artikel lesen
- Instagram Karussell vollständig erfassen mit MutationObserver: Lazy-Loading, Observer-before-click, Timeout-Fallback: Artikel lesen
- Notiz und Tags beim Screenshot-Speichern: Artikel lesen
- Instagram Tastatur-Shortcuts blockieren Chrome Extension Eingaben: Artikel lesen
- Lowercase-Normalisierung und Duplikat-Erkennung im Tag-Input: Artikel lesen
- Zitadel Login V2 in Docker Compose: drei versteckte Fehler: Artikel lesen
- PKCE OAuth in einer Chrome MV3 Extension: Artikel lesen
- React Frontend mit react-oidc-context und Zitadel: Artikel lesen
- Vite Build-Time-Umgebungsvariablen in Docker: Artikel lesen
- Event-Driven Ingestion mit BullMQ und Redis: Artikel lesen
- MinIO statt Azurite: S3-kompatible Objektspeicherung lokal und auf Hetzner: Artikel lesen
- access_token, id_token und der Userinfo-Endpoint: was wohin gehört: Artikel lesen
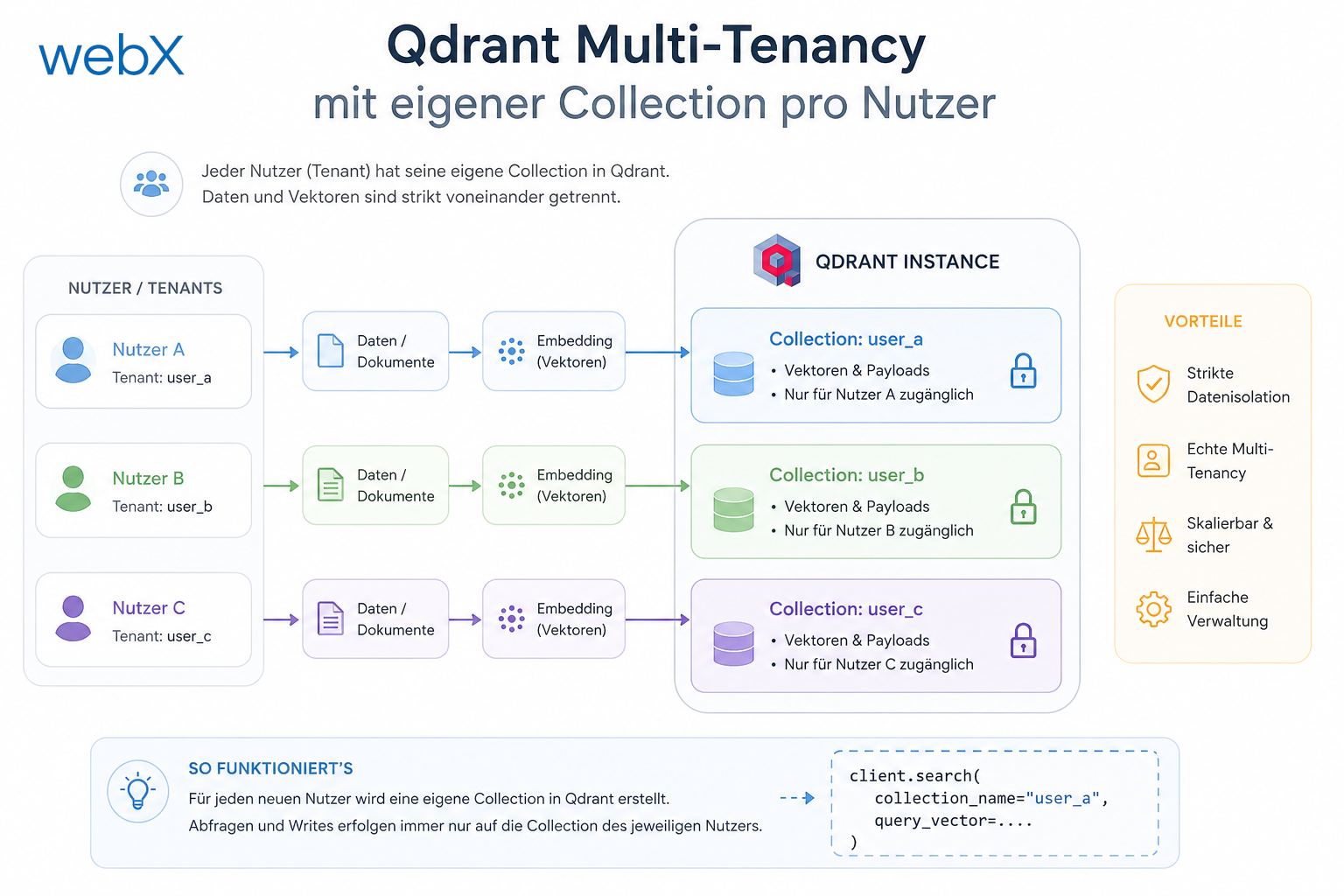
- Qdrant Multi-Tenancy: Pro Nutzer eine eigene Collection: Artikel lesen
- Wenn Backend und Frontend unterschiedliche Typen kennen: Artikel lesen
- Zitadel Bootstrap entfernt: Host-Header-Bug und manuelles Setup: Artikel lesen
- Backend Code Review: sechs Probleme vor dem Launch behoben: Artikel lesen
- Traefik statt NGINX: Reverse Proxy für einen wachsenden Docker-Compose-Stack: Artikel lesen
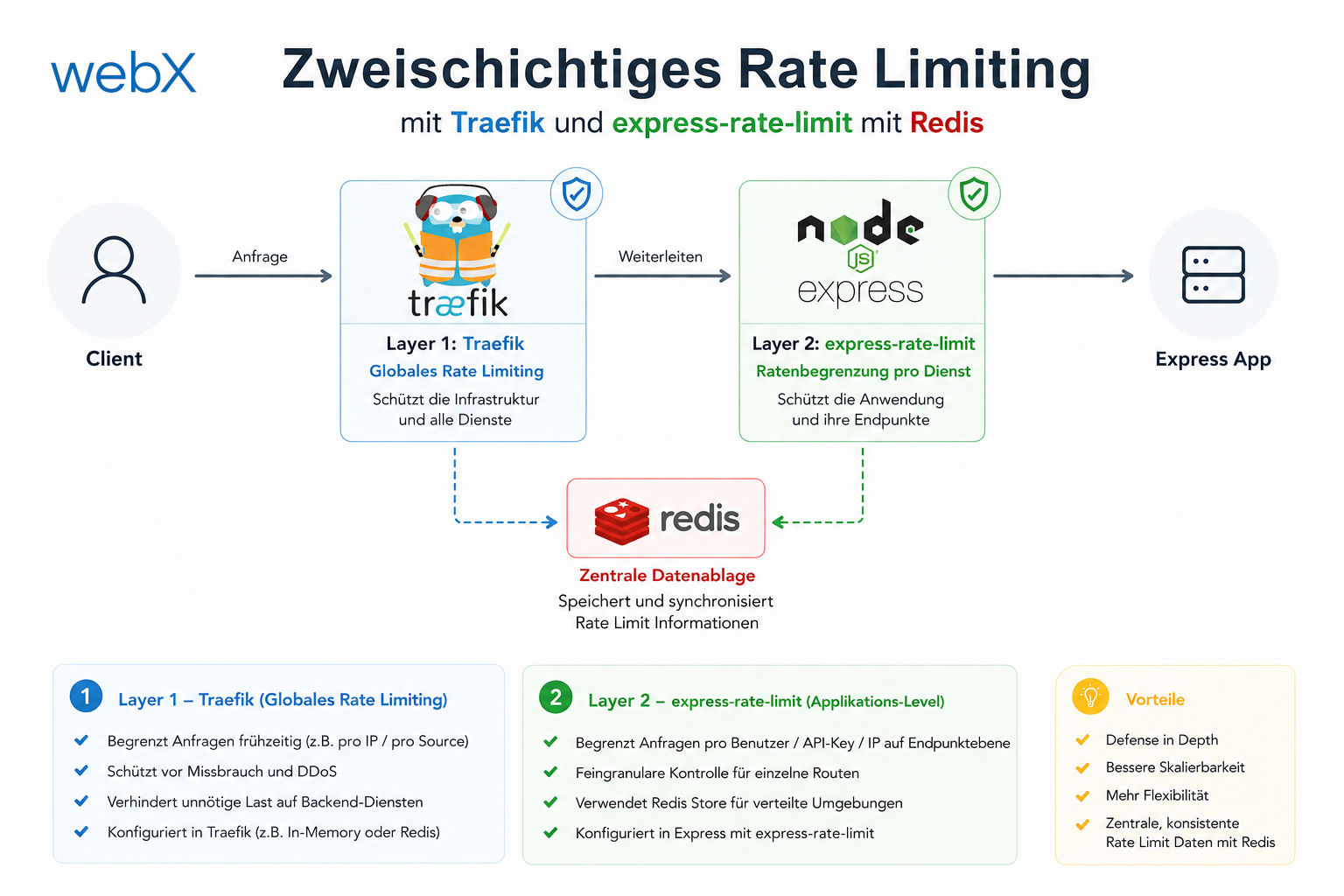
- Zweischichtiges Rate Limiting: Traefik und express-rate-limit mit Redis: Artikel lesen
- DSGVO Art. 17 korrekt implementieren: Promise.allSettled und Export-Batching (dieser Artikel)
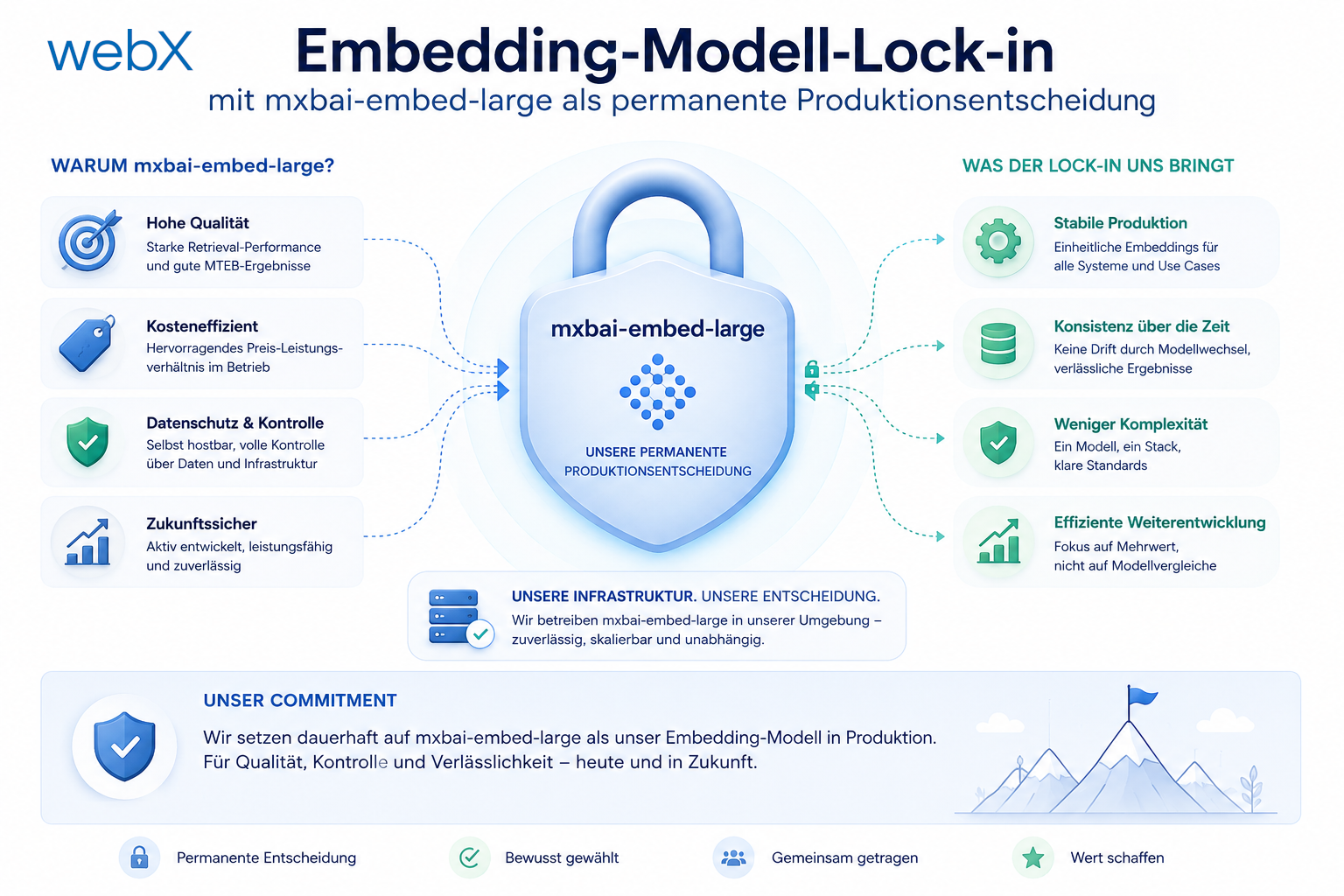
- Embedding-Modell-Lock-in: Warum mxbai-embed-large eine Produktionsentscheidung für immer ist: Artikel lesen
- Docker Volumes in Produktion: Named Volumes, Bind Mounts und der Hetzner-Volume-Trick: Artikel lesen
- Zwei Sicherheitslücken vor dem Launch: Redis ohne Auth und ein offener Qdrant-Admin-Port: Artikel lesen
Planst du einen Datenlösch-Endpoint und fragst dich, wie du DSGVO-Konformität unter Infrastrukturfehlern sicherstellst? Lass uns das gemeinsam einschätzen.